Витік даних у ШІ через співробітників
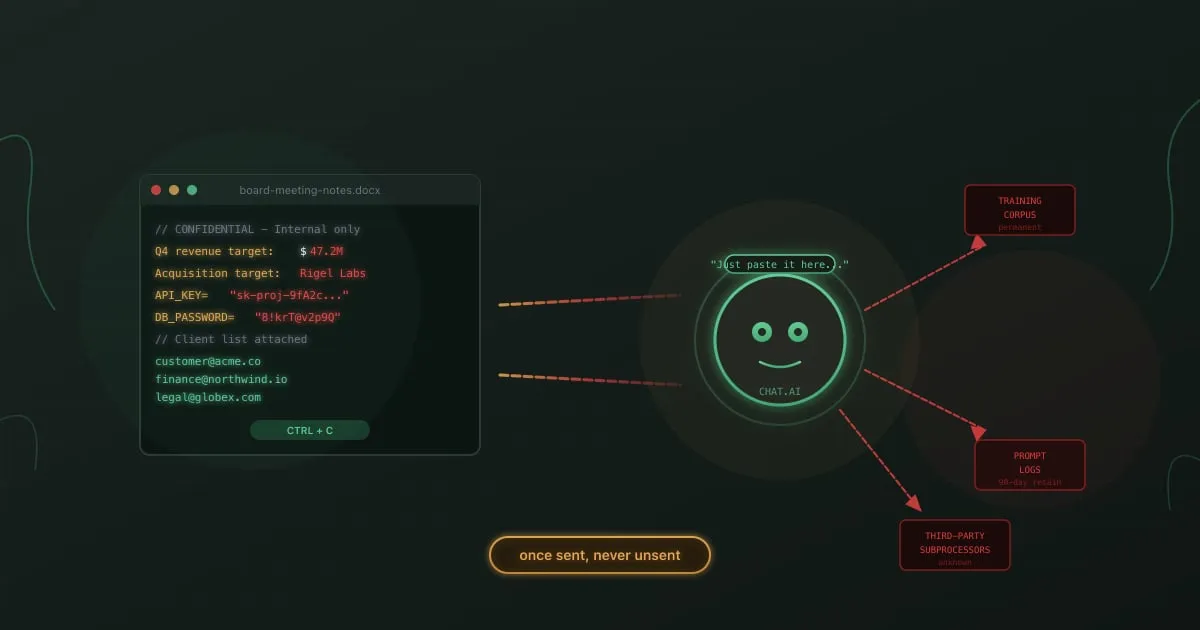
Напівпровідниковий підрозділ Samsung заборонив ChatGPT у травні 2023 року після того, як троє співробітників злили конфіденційні дані менш ніж за місяць. Один інженер вставив пропрієтарний вихідний код, щоб налагодити помилку. Інший надіслав нотатки з внутрішньої наради для генерації конспекту. Третій завантажив виміри виробництва чипів, щоб отримати розрахунок виходу. Кожен із них намагався робити свою роботу швидше. Кожен залишив копію комерційної таємниці Samsung на сервері OpenAI.
За кілька тижнів Apple, JPMorgan, Bank of America, Verizon, Amazon, Goldman Sachs та Deutsche Bank додали свої обмеження. Розрахунок був однаковим у кожній компанії. Продуктивний виграш був реальним, але реальним був і ризик того, що співробітники перетворюють споживчі інструменти ШІ на канал виводу даних, який ніхто не санкціонував.
Через два роки заборони помʼякшилися до політик, а політики помʼякшилися до прогалин у навчанні. Більшість співробітників досі не розуміють, що відбувається з текстом, який вони вставляють у вікно ШІ-чату. Це суть OWASP LLM02 — ризику розкриття чутливої інформації, який посідає друге місце в OWASP Top 10 для LLM-застосунків.
Що таке витік даних у ШІ?
Section titled “Що таке витік даних у ШІ?”Витік даних у ШІ — це розкриття конфіденційної, регульованої або пропрієтарної інформації для систем великих мовних моделей через взаємодію співробітників. Це трапляється, коли працівники вставляють чутливий вміст у споживчі ШІ-чат-боти, надають файли інструментам продуктивності з функціями ШІ або підʼєднують внутрішні системи до сторонніх ШІ-сервісів без належних контролів.
Злиті дані можуть зберігатися в логах промптів, векторних базах даних, памʼяті моделі або в майбутніх тренувальних датасетах залежно від політики зберігання постачальника. Аналіз активності 1,6 мільйона працівників знань від Cyberhaven 2023 року показав, що 11% контенту, який співробітники вставляли в ChatGPT, був конфіденційним, включно з вихідним кодом, даними клієнтів і регульованою інформацією.
На відміну від традиційних витоків, витік у ШІ рідко спричиняє алерти, бо трафік іде через зашифрований HTTPS до легітимних доменів. Дані виходять з організації тихо, по одному промпту за раз, через інструменти, які співробітники вважають помічниками роботи.
Як взагалі дані потрапляють у LLM?
Section titled “Як взагалі дані потрапляють у LLM?”Витік через співробітників відбувається через чотири окремих канали. Кожен потребує свого контролю.
Пряме вставляння промптів. Це і є сценарій Samsung. Співробітник копіює код, контракти, записи клієнтів, протоколи ради або стратегічні плани у вікно чату. Текст іде на сервери постачальника, обробляється для інференсу й залишається у логах запитів. На споживчих тарифах він може також потрапити в черги тренувальних даних.
Запамʼятовування тренувальних даних. Моделі можуть запамʼятати конкретний текст зі своїх тренувальних наборів і відтворити його буквально за правильного запиту. Дослідники Google DeepMind у 2023 році продемонстрували, що GPT-3.5 можна вмовити вивергнути адреси електронної пошти, номери телефонів і уривки з книжок, захищених авторським правом, через прості атаки повторень. Якщо ваш пропрієтарний вміст колись потрапить у тренувальний конвеєр, фрагменти можуть пізніше спливти в розмові іншої людини.
Підʼєднання застосунків з ШІ-функціями. Copilot, Gemini та подібні інструменти індексують пошту, документи й історію чатів, щоб їхні підказки були корисними. Неправильно налаштоване розгортання Copilot може розкрити документи, до яких співробітник не має доступу, показавши їх у результатах пошуку. Microsoft публічно визнав надмірне поширення як один з найбільших ризиків розгортання Copilot.
Сторонні інтеграції та розширення браузера. ШІ-помічники для письма, записувачі нарад і плагіни продуктивності обробляють контент, який бачать. Кожен створює новий потік даних до нового постачальника, часто під керівництвом умов надання послуг, по яких співробітник клікнув за двадцять секунд.
Вправа Sensitive Data Disclosure проводить співробітників через усі чотири сценарії в одній 15-хвилинній симуляції.
Чому Samsung насправді заборонив ChatGPT?
Section titled “Чому Samsung насправді заборонив ChatGPT?”Інциденти Samsung отримали більше уваги, ніж будь-які інші ранні кейси витоку даних у ШІ, і конкретику варто знати, бо вона показує, наскільки нормально виглядала поведінка з витоком.
В одному випадку інженер з напівпровідників хотів перевірити власний вихідний код на помилки. Він вставив його в ChatGPT із запитом на оптимізації. Код був частиною конфіденційного проєкту з дизайну чипа. В іншому співробітник надіслав запис внутрішньої наради, щоб отримати транскрипцію й конспект. Нарада містила стратегічні деталі, які не виходили за межі кімнати. Третій співробітник використав інструмент, щоб згенерувати презентацію з внутрішніх даних виходу продукції.
Жоден з цих співробітників не намагався завдати шкоди. Жоден не крав дані. Вони використовували популярний інструмент продуктивності так само, як використовували б Grammarly чи Google Translate, не усвідомлюючи, що споживчий продукт OpenAI на той час зберігав їхні вхідні дані для тренування. Витік стався у момент вставки, не пізніше через злам.
Реакція Samsung була негайною. Компанія видала письмове повідомлення, заборонила генеративний ШІ на корпоративних пристроях і мережах та оголосила плани побудувати внутрішню альтернативу. Порушення політики стало підставою для звільнення.
Ширший урок: якщо компанії зі зрілістю безпеки Samsung знадобилося менше місяця, щоб накопичити кілька інцидентів, типове підприємство стикається з подібним ризиком, не знаючи про нього.
Які типи даних витікають найчастіше?
Section titled “Які типи даних витікають найчастіше?”Звіт Cyberhaven і подальші дослідження від Harmonic, Menlo Security та Netskope зійшлися на схожих категоріях. Витік даних у ШІ через співробітників зазвичай концентрується у шести групах.
Вихідний код і технічна конфігурація витікають часто, бо розробники використовують ШІ для налагодження, рефакторингу та пояснення незнайомого коду. Злиті фрагменти часто містять API-ключі, облікові дані баз даних та внутрішні імена сервісів. Це перетинається з ширшим патерном, описаним у нашому матеріалі про ризики безпеки ШІ-асистентів для коду.
Дані клієнтів виходять через агентів підтримки, які пишуть відповіді, відділи продажів, які конспектують дзвінки, і маркетинг, який генерує розсилку. Імена, електронні адреси, номери рахунків та історії звернень подорожують до постачальника ШІ разом із промптом.
Фінансові дані зʼявляються, коли співробітники просять ШІ переформатувати таблиці, пояснити відхилення або скласти апдейт інвесторам. Цифри доходу, прогнози та пайплайни угод опиняються у логах.
Юридичні документи та контракти вставляють для конспекту, порівняння пунктів або перекладу простою мовою. Це часто включає NDA, а отже сам акт вставки може порушити угоду про конфіденційність.
Дані людських ресурсів витікають через написання відгуків за ефективністю, комунікацію про звільнення та оцінку кандидатів. Медичні дані, деталі компенсації та дисциплінарні записи витікають разом з промптом.
Стратегічний вміст, включно з матеріалами ради, продуктовими дорожніми картами й планами придбань, витікає, коли керівники та їхній штаб використовують ШІ, щоб відшліфувати презентації або витягнути ключові тези.
Чому традиційний DLP цього не ловить?
Section titled “Чому традиційний DLP цього не ловить?”Традиційні інструменти Data Loss Prevention були побудовані для моделі загроз, яка передує ChatGPT. Вони спостерігають за вкладеннями в пошту, передачею через USB, завантаженнями в особисті хмари та незвичайними переміщеннями файлів. Зі взаємодіями ШІ вони борються зі структурних причин.
Трафік виглядає легітимно. POST-запит до api.openai.com або chat.openai.com — це зашифрований HTTPS до відомого бізнес-домену. Якщо ви не робите SSL-інспекцію з кастомним кореневим сертифікатом на кожному ендпоінті, DLP-движок бачить зашифровані блоки, що йдуть на дозволений напрямок.
Вміст не є файлом. DLP-движки налаштовані виявляти виведення файлів: PDF, що виходять з мережі, таблиці, що завантажуються. Уривок тексту, вставлений у вікно чату, не спрацьовує на файлових контролях, бо файл ніколи не створювався.
Напрямок постійно змінюється. ChatGPT був першою ціллю, але тепер співробітники використовують Claude, Gemini, Perplexity, Copilot, Cursor і десятки менших інструментів. Блокування одного домену просто перекидає використання на наступний. Тіньовий ШІ йде тією ж кривою адаптації, яку ми описали у матеріалі про ризики безпеки тіньового ІТ.
Ризик поведінковий, а не технічний. Навіть якщо заблокувати всі домени ШІ на рівні мережі, співробітники використовуватимуть особисті пристрої, браузери телефонів або SSH-тунелі, щоб дістатися до інструментів, які вважають корисними. Прогалина в навчанні має закриватися разом із технічною.
Чи OpenAI, Anthropic чи Microsoft тренують на ваших промптах?
Section titled “Чи OpenAI, Anthropic чи Microsoft тренують на ваших промптах?”Це чи не найбільш заплутане питання в політиці даних ШІ, і відповідь залежить від того, яким тарифом продукту ви користуєтеся.
Для споживчих тарифів за замовчуванням раніше було тренування на вводі користувача, якщо користувач не відмовлявся. OpenAI змінив цей стандарт для ChatGPT у квітні 2023 року після новинного циклу Samsung. Споживчий Claude від Anthropic також дозволяє відмовитися. Google Gemini пропонує подібні контролі. Користувачі, які ніколи не чіпали налаштувань, можуть мати вміст у тренувальних чергах від своїх ранніх сесій.
Для бізнес- та enterprise-тарифів за замовчуванням тренування немає. ChatGPT Enterprise від OpenAI, Claude for Work від Anthropic, Microsoft Copilot з Commercial Data Protection і Gemini у Google Workspace усі контрактно зобовʼязуються не використовувати ввід клієнта для тренування моделей. Дані все одно логуються для моніторингу зловживань, але не входять у тренувальні конвеєри.
Для доступу через API більшість постачальників виключають дані API з тренування за замовчуванням. Ось тут різниця важлива найбільше для комплаєнсу: API-інтеграції, які будує ваша компанія, відрізняються від споживчого застосунку, який завантажують ваші співробітники.
Практичний висновок: те, на якому тарифі ваші співробітники, змінює, чи стане вставлений текст постійною частиною чиєїсь моделі. Більшість співробітників не мають уявлення, на якому вони тарифі.
Які контролі реально зменшують витік даних у ШІ?
Section titled “Які контролі реально зменшують витік даних у ШІ?”Ефективні програми поєднують чотири шари. Пропуск будь-якого створює очевидну прогалину.
Контрактні контролі означають купівлю enterprise-тарифів ШІ з угодами про обробку даних, які забороняють використання для тренування, обмежують зберігання та документують суб-обробників. Це основа. Споживчі тарифи залишають ваші дані в межах умов, які постачальник востаннє оновив.
Технічні контролі включають DLP-продукти, обізнані з ШІ, розширення браузера, які перехоплюють вставки в несанкціоновані ШІ-домени, та SSO-контрольований доступ, що спрямовує все використання ШІ через керовані тенанти. Microsoft Purview, Cyberhaven та Netskope тепер пропонують ШІ-специфічні DLP-модулі, але жоден з них не замінює політику й навчання.
Класифікаційні контролі спираються на здатність співробітників розпізнавати, які саме дані вони збираються поділитися. Вправа Data Classification Basics охоплює навичку розпізнавання напряму. Без грамотності в класифікації технічні контролі зводяться до рішень allow-or-block, які співробітники обходять, коли інструмент перестає бути корисним.
Навчальні контролі будують судження, що закриває останню прогалину. Кожна політика має крайні випадки. Кожен технічний контроль має сліпі зони. Співробітники, які розуміють, що відбувається з текстом, який вони вставляють, ухвалюють кращі рішення у тих моментах, які політика прямо не покриває.
Чотири шари посилюють один одного. Контракти задають стандарти з боку постачальника. Технічні контролі ловлять недбалі вставки. Класифікація допомагає співробітникам бачити, що вони тримають у руках. Навчання перетворює перші три на звичку.
Як тренувати співробітників на ризики витоку даних у ШІ?
Section titled “Як тренувати співробітників на ризики витоку даних у ШІ?”Читання політики не змінює поведінку. Так само як і відео, що пояснює, чому ChatGPT ризикований. Працює інше: дати співробітникам зробити помилку у безпечному середовищі й побачити наслідки.
Каталог навчання з безпеки ШІ RansomLeak охоплює повний OWASP LLM Top 10, але три вправи найбільш прямо мапуються на проблему витоку даних.
Вправа Sensitive Data Disclosure ставить співробітників у сценарій Samsung. Вони отримують правдоподібну бізнес-задачу, отримують доступ до симульованого ШІ-асистента й бачать, що трапляється, коли вставляють різні види вмісту. Розбір показує, куди пішли дані, скільки вони зберігатимуться і що вимагала класифікаційна політика.
Вправа System Prompt Leakage охоплює суміжний ризик виведення промптів, який має значення для будь-якої організації, що будує внутрішні продукти ШІ. Злиті системні промпти часто містять вбудовані облікові дані, API-ендпоінти та бізнес-логіку, яку компанія вважає конфіденційною.
Вправа Accidental Insider Threat торкається ширшого людського патерну: добронадійних співробітників, які завдають шкоди через короткі шляхи зручності. Витік у ШІ — це один випадок патерну, який також проявляється у листах з неправильною адресою, надмірно поширених хмарних папках і роздрукованих документах, залишених у публічних місцях.
Рольові шляхи допомагають. Інженерам потрібне глибше покриття витоку коду й експозиції API-ключів. Командам, що працюють з клієнтами, потрібна практика з PII у сценаріях підтримки. Керівникам потрібні сценарії з матеріалами ради й неоголошеним стратегічним вмістом. Навчання «один розмір підходить усім» пояснює політику, але не будує конкретного судження, якого потребує кожна роль.
Частота теж має значення. Постачальники змінюють свої стандарти кожні кілька місяців. Нові ШІ-функції зʼявляються всередині інструментів, якими співробітники вже користуються. Одноразове навчання у 2025 році не охоплює функції Copilot, випущені у 2026-му. Короткі повторення, привʼязані до змін в інструментарії, тримають навчання актуальним.
Питання, які enterprise-команди ставлять знову і знову
Section titled “Питання, які enterprise-команди ставлять знову і знову”Чи можна просто заблокувати ChatGPT на файрволі?
Можна, і багато підприємств зробили це у перший рік після запуску ChatGPT. Більшість з часом помʼякшила блок, бо співробітники перейшли на особисті пристрої, браузери телефонів або менші ШІ-інструменти, про які файрвол ще не чув. Мережеві блоки працюють як тимчасовий захід, поки ви будуєте контрактні й навчальні шари. Як стратегія вони не працюють.
Якщо ми користуємося ChatGPT Enterprise, чи вирішено проблему?
Enterprise-тарифи усувають канал витоку для тренувальних даних у цьому конкретному продукті. Вони не перешкоджають співробітникам користуватися особистими акаунтами ChatGPT, підʼєднувати несанкціоновані ШІ-розширення браузера чи вставляти дані в будь-який новий ШІ-інструмент, який вийшов минулого тижня. Enterprise-контракт — один шар, а не вся програма.
Чим витік даних у ШІ відрізняється від загального запобігання витоку даних?
Традиційний DLP будувався навколо переміщення файлів і відомих патернів виведення. Витік у ШІ відбувається через копіювання й вставлення у зашифровані веб-сесії з легітимними постачальниками зі швидкістю гарячої клавіші. Архітектура контролів має бути іншою, а навчальний зміст має покривати ризики, яких не існувало, коли більшість DLP-програм проєктували.
Чи є витік даних у ШІ проблемою GDPR?
Так. Персональні дані, вставлені в інструмент ШІ, — це подія обробки за GDPR. Постачальник ШІ стає обробником. Якщо юридичну підставу не задокументовано, угоду про обробку не укладено або міжнародну передачу не покрито, компанія має проблему з комплаєнсом на додаток до проблеми з безпекою. Вправа GDPR data breach response покриває таймлайн повідомлення, коли витік сягає порогу інциденту.
Нам варто тренувати на цьому чи просто блокувати?
Потрібні обидва. Блокування без навчання створює обхідні шляхи. Навчання без блокування створює непослідовне виконання. Поєднання enterprise-контрактів, DLP, обізнаного зі вставкою, грамотності в класифікації та сценарних вправ дає зміну поведінки, якої жоден з контролів поодинці не дає.
RansomLeak покриває повний OWASP Top 10 для LLM-застосунків через 10 інтерактивних вправ. Почніть зі сценарію Sensitive Data Disclosure, сформуйте звичку sanitize-first у Безпечному використанні GenAI, або закрийте суміжні шляхи витоку даних з Чутливістю логів та Усвідомленням метаданих. Перегляньте повний каталог навчання з безпеки ШІ для інших вправ.
Джерела
Section titled “Джерела”- OWASP Top 10 for LLM Applications 2025
- Bloomberg: Samsung Bans Staff’s AI Use After Spotting ChatGPT Data Leak
- Cyberhaven: How Employees Are Using ChatGPT at Work
- Reuters: Apple Restricts Use of ChatGPT, Joining Other Companies Wary of Leaks
- Google DeepMind: Scalable Extraction of Training Data from Language Models
- Microsoft: Data, Privacy, and Security for Microsoft Copilot
- OpenAI: Enterprise Privacy